- Đăng vào
Crawl dữ liệu tỷ giá hối đoái với AWS Lambda và DynamoDB (Over engineer version)
- Tác giả

- Name
- Quang Mau
- @qmauvnt

Mục lục
TL;DR
Giải pháp đơn giản cho yêu cầu crawl dữ liệu đơn giản 😅
Yêu cầu
Một ngày đẹp trời, bà chị gái yêu dấu của tôi có chia sẻ nỗi trăn trở làm sao để lấy được tỷ giá của 3 ngân hàng Việt Nam trong 5 tháng gần nhất. Là một người em trai có hiếu thì không thể không giúp chị gái mình được. Đấy là người bình thường sẽ nghĩ thế, nhưng tôi thương cháu tôi nhiều hơn. Để mỗi ngày những người cháu có thêm thời gian được mẹ chăm sóc và dạy dỗ. Tôi quyết định viết một crawler nhỏ để giúp chị tôi.
Dưới đây là yêu cầu từ mẹ của cháu tôi:
- Lấy tỷ giá hối đoái 5 tháng gần nhất
- Lấy tỷ giá các ngày tiếp theo sau hôm nay
- Dữ liệu được lưu dưới dạng có thể mở được bằng Excel
Ngoài ra có thêm 1 yêu cầu nho nhỏ tôi tự thêm vào
- Không tốn tiền hoặc tốn rất ít vì tôi không được trả tiền cho việc này. Cháu tôi còn quá nhỏ để hiểu được sự hi sinh lớn lao của cậu nó 😅
Giải pháp
Sau một hồi bối rối trước cấu trúc HTML và cách truyền params của ngân hàng S, tôi quyết định chọn cách làm đơn giản:
-> Dữ liệu 5 tháng đầu sẽ được crawl trên máy cá nhân sử dụng selenium để thao tác với forms, dữ liệu các ngày tiếp theo sẽ được crawl bằng lambda function vì không yêu cầu tương tác trên trang web.
Việc phát triển 1 crawler sử dụng headless browser trên lambda sẽ tốn thời gian mà tôi thì không được trả tiền 🤡
Đây sẽ là giải pháp cho yêu cầu phía trên:
- Crawler viết bằng python sử dụng BeautifulSoup, requests cho bank M, B, riêng bank S sẽ có thêm selenium.
- Một serverless application sử dụng AWS Lambda để crawl dữ liệu những ngày tiếp theo (build với AWS Serverless Application Model)
- Dữ liệu crawl được lưu tại DynamoDB
- API để download csv được tạo từ DynamoDB, filter theo params là ngày đầu và ngày cuối
Lý do sử dụng DynamoDB lưu dữ liệu chứ không phải S3 để lưu CSV file:
- S3 không hỗ trợ việc append vào file. Nếu sử dụng muốn append s3 với Lambda function = phải download file -> append vào file -> xoá file và reupload. Giải pháp đơn giản nhưng tốn tiền là dùng Kinesis Firehose.
- Nếu sử dụng s3, việc filter dữ liệu theo ngày sẽ không đơn giản bằng dùng DynamoDB
- Vì nó miễn phí (< 25GB storage)
Diagram phức tạp của giải pháp cho yêu cầu crawl dữ liệu đơn giản 😅
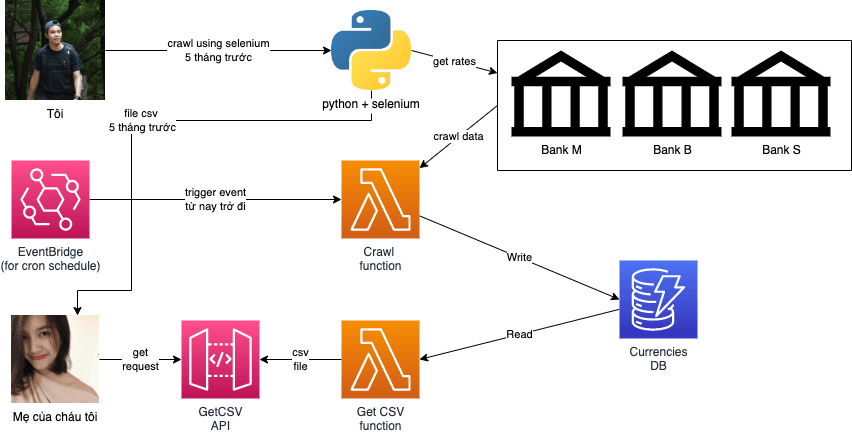
Triển khai
SAM local
- Cài đặt SAM CLI
- Tạo project currency-crawler
sam init --name currency-crawler --runtime python3.9
- Setup AWS credentials
vi ~/.aws/credentials
[vntechies]
aws_access_key_id=******
aws_secret_access_key=******
- Tạo template cho hệ thống sử dụng SAM
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: >
currency-crawler
Sample SAM Template for currency-crawler
# More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst
Globals:
Function:
Timeout: 100
Resources:
CurrencyCrawlFunction:
Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction
Properties:
CodeUri: currency/
Handler: app.crawl
Runtime: python3.9
Architectures:
- x86_64
Events:
InvocationLevel:
Type: Schedule
Properties:
Schedule: cron(0 11 ? * MON-FRI *) # All scheduled events use UTC+0 time zone
DeadLetterConfig:
Type: SQS
Policies:
DynamoDBWritePolicy:
TableName: !Ref CurrencyTable
CurrencyGetFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: currency/
Handler: app.get_csv
Runtime: python3.9
Architectures:
- x86_64
Events:
CurrencyCrawler:
Type: HttpApi # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api
Properties:
Path: /csv
Method: get
ApiId: !Ref CurrencyHTTPApi
Policies:
DynamoDBReadPolicy:
TableName: !Ref CurrencyTable
CurrencyHTTPApi:
Type: AWS::Serverless::HttpApi
Properties:
CorsConfiguration:
AllowOrigins:
- "*"
AllowHeaders:
- "Content-Transfer-Encoding"
AllowMethods:
- GET
CurrencyTable:
Type: AWS::Serverless::SimpleTable
Properties:
PrimaryKey:
Name: dt
Type: String
#ProvisionedThroughput:
TableName: "Currency"
Outputs:
# https://github.com/awslabs/serverless-application-model/blob/master/docs/internals/generated_resources.rst#api
CurrencyCrawlApi:
Description: "API Gateway endpoint URL for Prod stage for Hello World function"
Value: !Sub "https://${CurrencyHTTPApi}.execute-api.${AWS::Region}.amazonaws.com/crawl/"
CurrencyCrawlFunction:
Description: "Hello World Lambda Function ARN"
Value: !GetAtt CurrencyCrawlFunction.Arn
CurrencyCrawlFunctionIamRole:
Description: "Implicit IAM Role created for Hello World function"
Value: !GetAtt CurrencyCrawlFunctionRole.Arn
Một số lưu ý
- Lambda function connect được với public Internet by default
DynamoDBReadPolicy,DynamoDBWritePolicyassign quyền đọc và ghi tới DynamoDB với từng functionAWS::Serverless::HttpApisử dụng HTTP API thay vì REST API vì chỉ cần Regional access và không cần những tính năng của REST API -> giảm chi phícron(0 11 ? * MON-FRI *)schedule cron sử dụng múi giờ UTC+0Content-Transfer-Encodingcác request download file từ Lambda funtion sẽ có size limit là 6MB và cần được mã hoá base64 -> cần allow header này tại HTTP APIProvisionedThroughputcủa DynamoDB: nếu khai báo pricing model sẽ là provisioned, nếu để trống thì model sẽ là on demand
Viết các hàm crawler cho các banks. Nếu bạn quan tâm có thể tham khảo source code tại đây.
Test & Validate & Build & Deploy
# test function bằng event mẫu từ EventBridge
sam local invoke "CurrencyCrawlFunction" -e events/event.json
# validate SAM template
sam validate --profile vntechies --region ap-southeast-1
# build package
sam build
# deploy
sam deploy --guided --profile vntechies
Chores
- Viết script lấy dữ liệu cho 150 ngày trước đó (trừ cuối tuần). Lấy đại diện bank S, tôi phải dùng headless browser vì cấu trúc hơi phức tạp 🥲
bs4
pandas
selenium
webdriver_manager
requests
cd crawl_old_data
pip install -r requirements.txt
vi scb.py
from decimal import Decimal
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from datetime import date, datetime, timedelta
from bs4 import BeautifulSoup
from selenium.common.exceptions import TimeoutException
import pandas as pd
import pdb
CURRENCIES = ['USD', 'EUR', 'JPY', 'AUD', 'HKD', 'SGD']
def get_record(requested_date_str, driver):
driver.find_element(By.CSS_SELECTOR, "#dtpNgayMoney > span > i").click()
title = driver.find_element(
By.CSS_SELECTOR, "ul > li > div > div > table > thead> tr > th:nth-child(2)")
previous_button = driver.find_element(
By.CSS_SELECTOR, "ul > li > div > div > table > thead> tr > th:nth-child(1)")
next_button = driver.find_element(
By.CSS_SELECTOR, "ul > li > div > div > table > thead> tr > th:nth-child(3)")
current_month = int(title.text.split(' ')[1])
requested_date = datetime.strptime(requested_date_str, '%d/%m/%Y').date()
while requested_date.month < current_month:
previous_button.click()
current_month = int(title.text.split(' ')[1])
while requested_date.month > current_month:
next_button.click()
current_month = int(title.text.split(' ')[1])
cal_body = driver.find_element(
By.CSS_SELECTOR, "div.datepicker-days > table > tbody")
cal_body.find_element(
By.XPATH, f"//td[text()='{requested_date.day}']").click()
sleep(5)
delay = 3 # seconds
try:
WebDriverWait(driver, delay).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#bdUSDG7 > table')))
print("Page is ready!")
except TimeoutException:
print("Loading took too much time!")
table = driver.find_element(By.CSS_SELECTOR, "#bdUSDG7 > table")
content = table.get_attribute('innerHTML')
soup = BeautifulSoup(content, features="html.parser")
items = soup.findAll("tr", {"class": "tr-items"})
record = {
"bank": "STB",
"date": requested_date.strftime("%Y-%m-%d")
}
for item in items:
currency = item.find(
"td", {"class": "td-cell01"}).contents[1].replace(' ', '')
if currency in CURRENCIES:
rate = item.find("td", {"class": "td-cell04"}
).contents[0].replace('.', '').replace(',', '.')
record[currency] = Decimal(rate)
return record
end_date = date.today()
current_date = end_date + timedelta(days=-150)
delta = timedelta(days=1)
docs = []
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://www.**.com.vn/company/Pages/ty-gia.aspx")
while current_date <= end_date:
if current_date.weekday() > 4:
print("Skip weekends")
current_date += delta
continue
current_date_str = current_date.strftime("%d/%m/%Y")
print(f"getting data for {current_date_str}")
docs.append(get_record(current_date_str, driver))
current_date_str
current_date += delta
sleep(2)
df = pd.DataFrame(docs)
df.to_csv('scb_rates.csv', index=False, header=True)
print("Completed!")
- Chạy script này cùng các script khác (source code tại đây)
python scb.py
python mbb.py
python bidv.py
- Dữ liệu của 5 tháng trước đã xong ✅
- EventBrigde trigger Lambda function lấy dữ liệu ✅
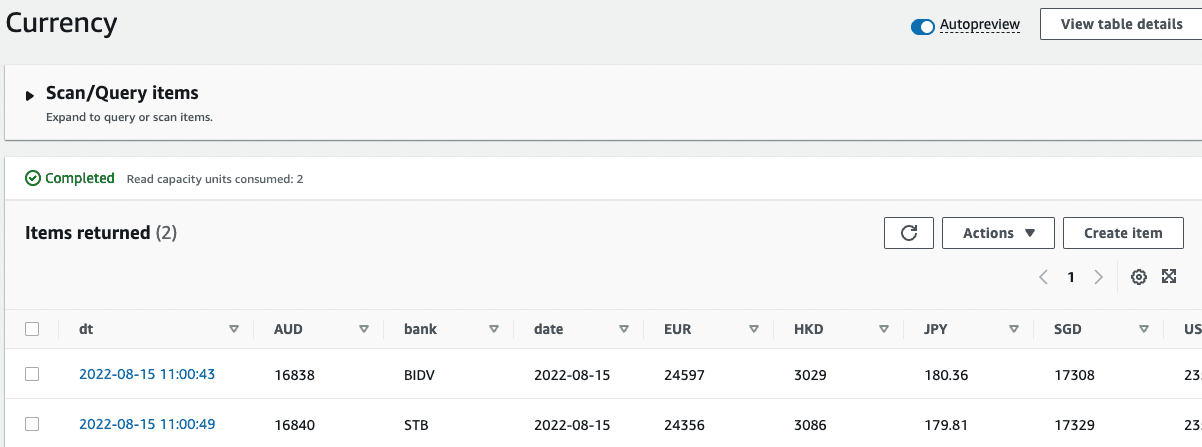
- Bà chị gái yêu dấu của tôi download dữ liệu bằng địa chỉ mà tôi đã gửi 🙈
Improvements
Thứ mà tôi sẽ không làm vì như đã trình bày, tôi không được trả tiền cho việc này 😂
- Xử lý lỗi cho các HTTP requests tới các site của banks đề phòng trường hợp bank nào đó bật maintainance mode hoặc thay đổi giao diện, handle dead letter queue
- Đánh index cho bảng Currency, sử dụng query thay vì scan để giảm chi phí (nếu phát sinh), sử dụng DynamoDB update expressions xử lý việc ghi đè dữ liệu nếu có
- Sử dụng Authentication cho các APIs
- Headless browser trên Lambda
- Unit tests và integration tests, tạo các môi trường phát triển khác (dev, staging,...)
- Handle file size limit từ Lambda (6MB). Cũng là lời nhắn nhủ với chị gái, đừng download dữ liệu > 12 tháng. 🙄
Như title đã nói, giải pháp này cồng kềnh và hơi gượng khi sử dụng dao mổ trâu để giết ruồi, có rất nhiều phương án tốt hơn hoặc đơn giản hơn cho yêu cầu này. Tuy nhiên, bằng giải pháp overengineering này mà mình cũng biết thêm, catch up lại một số kiến thức liên quan tới serverless application, lý do chính lớn hơn là còn có cớ để viết bài và thể hiện tâm huyết với người chị gái :)
Cuối cùng thì, các bạn hãy cân nhắc tới việc automate những task hằng ngày bằng python hoặc sử dụng serverless application cho cronjob nhé 😬
References
- Troubleshoot networking issues in Lambda
- Handling binary data using Amazon API Gateway HTTP APIs
- Choosing between REST APIs and HTTP APIs
VNTechies Dev Blog
Kho tài nguyên mã nguồn mở với sứ mệnh đào tạo kiến thức, định hướng nghề nghiệp cho cộng đồng Cloud ☁️ DevOps 🚀

Tham gia group VNTechies - Cloud ☁️ / DevOps 🚀 nếu bạn muốn giao lưu với cộng đồng và cập nhật các thông tin mới nhất về Cloud và DevOps.
- Website: https://vntechies.dev
- Github repository: https://github.com/vntechies
- Facebook page: https://facebook.com/vntechies

Anh chị em hãy follow/ủng hộ VNTechies để cập nhật những thông tin mới nhất về Cloud và DevOps nhé!